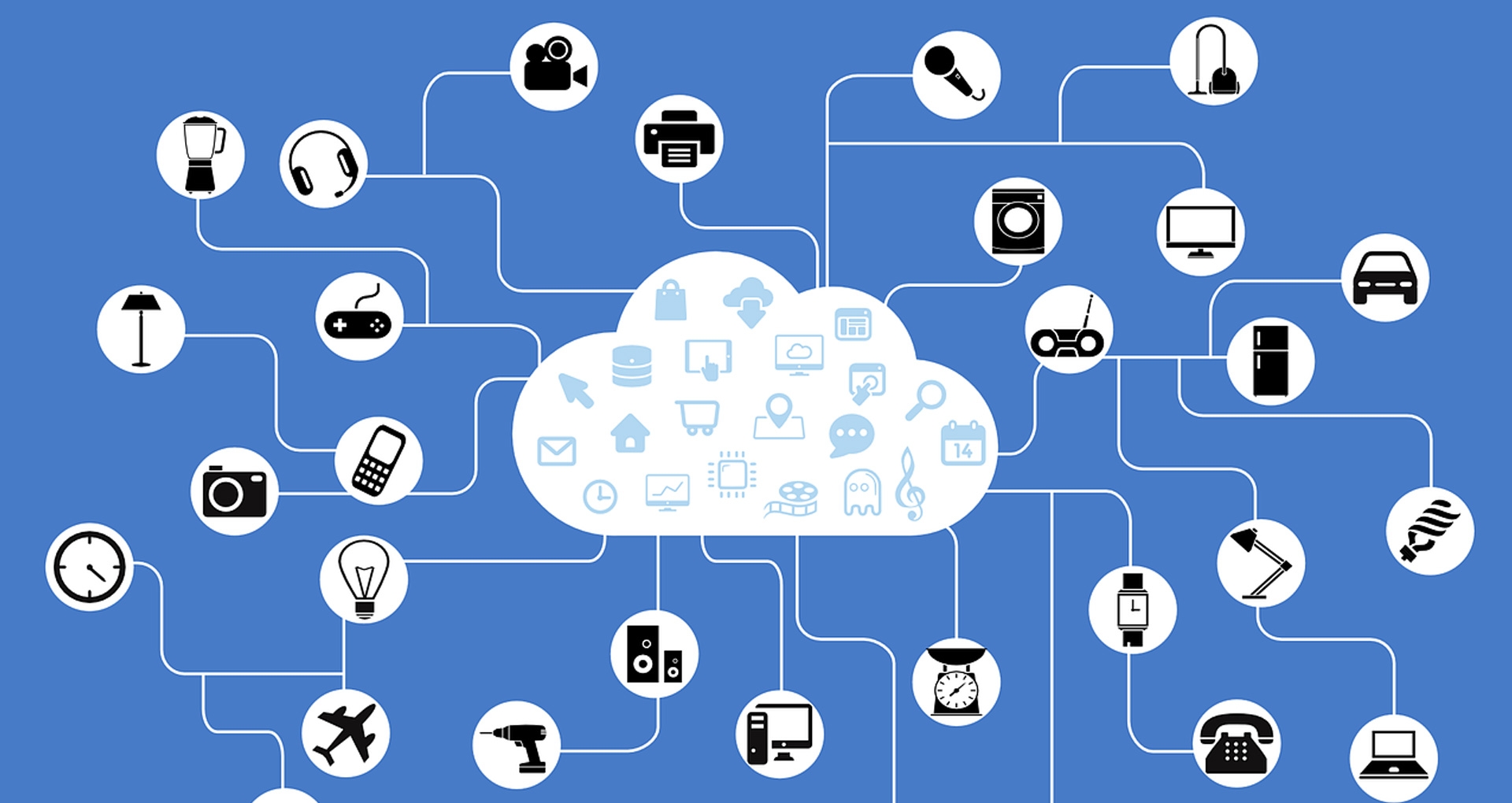


A long, long time ago, at the end of last year, we discussed various trends that would emerge and possibly define 2014 in online terms. Last year, as with every year, was full of buzzwords and two of the hottest Internet of Things and Big Data.
The Internet of Things is as literal as it sounds: essentially a collective term for all of the electronic sensors capable of delivering data back to a source for comparison. Fitness monitors that measure heart rates and smartphones with GPS being two of the most common. The problem has been that although there are vast numbers of them (predictions for around 6 billion ‘Things’ by 2015 are about average, depending on your definition) they were simply that – a number. This huge collection is a bit like Smarties in a tube – only connected by proximity. If you can find a way of connecting them, will patterns emerge?

But that could be about to change following an announcement by Stephen Wolfram, the man behind Wolfram|Alpha, Mathematica and many others. On January 6, Wolfram Research launched the Wolfram Connected Devices Project – an ongoing effort to amalgamate the disparate sensors of the Things into a single catalogue. Initially this will enable direct comparison between associate devices e.g. ‘All smartphones priced between £200 to £250 with a camera of 10mp or greater’. So far, so another list. But that’s just phase one of a larger plan. What Wolfram is trying to do is create a way of interacting with individual devices and harvesting specific data.
“Our goal is … to connect to the devices, and get data from them—and then do all sorts of things with that data. How can one actually interact with the device? Well, within the Wolfram Language we’ve been building a powerful framework for this … there are a standard set of Wolfram Language functions that perform operations related to the device. The goal is to get seamless integration of as many kinds of devices as possible. And the more kinds of devices we have, the more interesting things are going to get. Because it means we can connect to more and more aspects of the physical world, and be in a position to compute more and more about it.” - Stephen Wolfram
On the other side of the Deep Blue sea… Meanwhile, IBM has started a $100m venture capital fund for its Watson supercomputer, which has been relocated to Cloud computing for access by developers worldwide. Watson achieved a level of celebrity several years ago when it beat human rivals in US game show Jeopardy! But quickly disappeared from the consciousness of the general public.
Recently it has come back into the spotlight with headlines featuring large sums of money as IBM attempts to commercialise Watson. The problem seems to be that in order to get the most from Watson, large amounts of data need to be uploaded by a human. But what if Big Data were available directly from the source? Instead of the need for huge spreadsheets to be uploaded by hapless data inputters in darkened rooms, Watson was able to gather information directly from live sensors?
Could search history come back to haunt Google?
Computers were first valued for the speed at which they could perform mathematical calculations; currently the major players are software that is exceptionally good at information retrieval. Algorithms contained in Google and Facebook have enabled a level of information sharing that few would have thought possible even ten years ago. But ten years from now could the playing field look very different, with searching for past papers seeming archaic? Projects such as Watson and the Wolfram Connected Devices Project offer a glimpse of what might be possible. Not just the ability to find a specific answer located in an uploaded thesis, but the power to take two existing sources of information and generate entirely new data. The difference between adding up number to create a total, and adding together elements, causing a reaction and creating a new compound.

Cognitive computing is a buzzword still more closely associated with science fiction rather than current research, but companies such as IBM believe it will be the only way to approach the arrival of Big Data. According to IBM, ‘Data volume, velocity, and variety is growing at an astounding rate with a full 90% of the world's data less than two years old. But most of this data (as much as 90%) is unstructured meaning that it does not sit in database rows and columns and is therefore off limits to most traditional computing systems. Building capabilities in text analytics, and natural language processing can help bridge this gap to open up access to a world of new, valuable information as well as increase the speed to value of future Watson implementations.
What the future could have in store If cognitive computers such as Watson could learn enough to know what they don’t know, but instead of accessing archives to solve problems, were able to access the raw data itself via a fully connected Internet of Things, what would it be able to tell us? Would it be able to help predict and offer solutions to problems such as global warming or as yet unidentified pandemics? Could it extend our reach further into the cosmos via the research sensors on space probes, combining new datasets with decades of theoretical research and finding ways to, for example, protect astronauts from radiation and enable manned flights to Mars? With the IBM Watson project moved online, and a catalogued and connected Internet of Things speaking the same Wolfram Language, would it be possible to create an electronic ecosystem instead of a microsystem? Wolfram already has a history of collaboration with people such as Steve Jobs, and his Mathematica was bundled on to NeXT systems, some of which ended up at CERN where they used as the first web server for the modern internet. It’s safe to say Dr Wolfram 'has form' then.
That's Mr Watson to you. More recently he has expressed an interest in working with IBM on their Watson project. In the words of Ken Jennings, one of the contestants on Jeopardy who was defeated by Watson, ‘I for one welcome our new computer overlords’.
© 2026 A&M Consulting Ltd t/a Somerset Design. Registered in England and Wales. Company No. 4377058 VAT Reg. 803 6289 32 Site Info